|
資料來源:
https://doi.org/10.1098/rsbl.2017.0660
摘要
世界上
90% 的數據是在過去 5
年中生成的(機器學習:通過示例學習的電腦的力量和前景。報告編號 DES4702。2017
年 4
月發布。皇家學會)。收集這些數據的一小部分是為了驗證特定的假設。這些研究是由專注於投入產出關係因果關係的機械式式模型的發展所引領的。然而絕大多數目的在支持繞過因果關係的需要並專注於預測的統計或相關研究。沿著這些思路,機器學習模型的使用已經大大增加,特別是在生物醫學和臨床科學中,以試圖跟得上數據生成的速度。最近的成功,現在引出了一個問題,即機械式式模型是否仍然與該領域相關。換句話說,當我們可以使用機器學習工具直接預測疾病結果時,為什麼還要嘗試了解疾病進展的機制呢?
機器學習模型通過瀏覽給定問題的輸入和輸出數據庫來預測複雜機制的結果。 Tom Mitchell
等作者將機器學習定義為基於電腦的過程,該過程可以根據經驗提高其在給定任務上的性能
。這種體驗可能來自與先前收集的數據的交互或來自執行任務時與環境的交互。雖然這種方法強烈強調機器學習的人工智慧視角,但其他領域如數據庫社區,將機器學習視為更廣泛的“從數據庫中發現知識”過程的演算法部分(一個相當過時的術語,現在稱為數據採礦)[
為了提供準確的預測,機器學習模型需要大量數據或與環境的密集交互、適當演算法的選擇以及感興趣的輸入和輸出的識別。通過使用大規模數據集避免需要理解複雜機制的能力,使機器學習演算法在例如臨床環境中進行預測時具有可擴展性和高效性。最近的一個臨床例子是將Google的
DeepMind 技術應用於 160 萬份
NHS 患者記錄。這一舉措促成了智慧手機 app Streams
的開發,目的在解決“救援失敗”問題,即沒有足夠快地識別出健康惡化的警告信號或採取行動
雖然機器學習模型可用於從給定輸出的大數據集中分離相關輸入,但機械式建模依賴於通過觀察感興趣的現像,生成因果機制的新假設。其目的是通過對突出的潛在機制的假設來模擬現實生活中的事件。通常這涉及構建因果機制的簡化數學公式,並開發和/或使用分析工具來確定模型預測的可能輸入-輸出行為的範圍以及因果假設是否與實驗觀察結果一致。與機器學習模型一樣,機械式建模依賴於兩個階段的過程:首先可用數據的一個子集用於構建和校正模型;隨後,在驗證階段,進一步的數據用於確認和/或改進模型,從而提高其準確性。理想情況下,所得到的機械式式模型可用於後續無法或難以實現實驗的應用中。
工作提供了機械式建模方法的範例。Hodgkin & Huxley的神經動作電位產生模型是有史以來最成功的複雜生物過程數學模型之一。他們的模型在現象學上解釋了獨立離子通道的動力學,其中電流完全由沿電化學梯度向下移動的離子攜帶。使用一系列實驗對其進行校正和驗證,以確定離子通道的宏觀參數(例如電導、平衡電位、每種離子通道的動力學)。Hodgkin
& Huxley的工作為他們贏得了 1963
年的諾貝爾獎。該工作已得到廣泛應用,推動了我們對從單細胞生物到我們大腦中的神經元等範圍內細胞電活動的理解的界限,如心臟力學。Hodgkin
& Huxley能夠為科學家們提供關於神經細胞如何工作的基本了解。此外他們的模型通過推導可激發系統的簡單漫畫模型,激發了大量的應用數學研究。
機器學習和機械式建模方法依賴於不同類型的數據並提供對不同類型資訊的訪問。簡而言之,它們是兩種不同的範式。我們建議,從這個意義上說,它們不應被視為直接競爭對手或直接排斥另一個競爭對手。雖然機械式式模型提供了機器學習方法所缺少的因果關係,但它們過於簡單的假設和極其具體的性質阻礙了機器學習可實現的普遍預測。然而一個的優點是另一個的缺點,這表明研究工作應該致力於實現兩者之間的共生關係。回到前面的例子,Hodgkin
& Huxley
專注於開發魷魚巨軸突產生的動作電位的定量模型,隨後開發了該模型的多種變體來描述大量離子通道的動力學。然而,為所有可能的神經元校正Hodgkin
& Huxley模型的努力仍然是不切實際的,因為這種方法無法承受最近發現的新型離子通道的加速
( http://channelpedia.epfl.ch )。現有的全球神經科學倡議所遇到的阻礙進展的障礙充分證明了這一點。然而人們可以想像在未來實現一種適用於所有離子通道的通用模型,其中單個參數校正和模型改進將依賴於機械式框架之上的機器學習層。更一般地說,可以利用機器學習研究來克服目前機械式建模的可擴展性限制,而機械式式模型可以被機器學習演算法用作瞬態輸入和驗證框架。
然而,這種婚姻並不總是直截了當的,尤其是在臨床環境中。機器學習技術使用患者數據庫從過去的觀察中預測個體患者結果的任何嘗試都可能能夠識別現有治療中哪種最合適,但本質上無法建議新的治療方案或為新的治療提供準確的預測。在文獻中這方面被稱為學習演算法的“歸納能力”。從過去的數據中,可以識別數據中發生的模式。這與機械式式模型的演繹能力大不相同,其中邏輯(機械式)原理的組合可以推斷出原始數據中不存在的行為的預測
簡而言之,機制模型可以提供對治療機制功能的洞察和理解,這些對於克服機器學習預測的局限性是必要的。最近的一個例子是使用機器學習來預測內窺鏡第三腦室造口術用於治療腦積水的成功率
[ 5 ]。雖然該演算法可以預測實際手術的成功率,但它無法考慮其他一般生理變數對特定患者的風險,從而使該手術比另一個更受青睞。任何患者的確切風險取決於許多其他變數,因此只能在床邊對哪種手術更可取進行臨床評估。為了能夠比較患者的整體狀態,未來的風險和必要的治療需要“整體”理解,並且不能僅使用基於患者數據的機器學習模型來提供。
雖然基礎細胞生物學領域是我們對疾病理解的所有進步的基礎,但它幾乎不受機器學習技術進步的影響。造成這種情況的原因之一是它傳統上依賴於低吞吐量的數據生成方式,重點是建立少量的輸入-輸出關係。通過識別這些關係產生的機制假設通常可以使用簡化的機制模型自然地進行詢問,並建立因果機制。最近高通量數據收集方法的爆炸式增長加強了細胞生物學的“蝴蝶收集”性質,通常是負面看法。然而社區仍然專注於建立機械式理解。數據和目的之間的這種二分法通常會導致大量潛在機制模型的發展,這些模型可以解釋更大圖景的一小部分。雖然這些機械式式模型有可能被組裝為更大的機器學習演算法的輸入,但在這個方向上仍然缺乏認真的努力。
有兩種協同方式可以將機械式和機器學習方法結合起來。首先,在機械式建模方法中,從數據中學習特定組件。一個例子是使用代理模型進行多尺度模擬:從詳細模擬產生的數據中獲得的機器學習模型。在這裡只對詳細模型進行少量模擬(為了學習模型),然後使用近似代理模型進行未來預測。這種方法主要用作加速昂貴的計算多尺度模擬的方法。其次在基於機器學習的管道中,輸入資訊是由機械式方法生成的派生參數豐富的原始數據(以同樣的方式,改進的概率模型受益於對“隱藏變數”的更多資訊估計)。
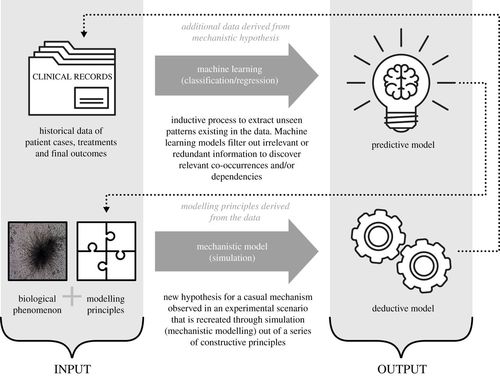
圖
1. 機器學習和機械式建模方法的輸入和輸出,以及兩者之間協同作用的潛力。
機器學習方法和機械式建模在細胞生物學中的整合可以在例如使用多變數資訊量測(如部分資訊分解)從單轉錄組數據中識別基因之間的假定功能關係中找到。然後可以使用機械式建模方法來測試學習的(假設的)基因調控網絡的有效性,作為測試-預測-改進-預測循環的一部分,這在生物科學中非常重要。使用這種方法的一個例子是識別在胚胎幹細胞分化的早期階段如何重新配置多能性調節網絡。然而,在將機器學習和機械式建模方法結合起來以在生物科學中發揮最佳效果方面還有很多工作要做。
在基礎生物學研究中整合機器學習和機械式建模方法缺乏進展,這與臨床社區廣泛採用機器學習方法相矛盾。事實上,許多新模型和演算法自然會在臨床場景中找到它們的第一個應用。這種協作的差異當然源於人們可以相對容易地定義臨床問題的輸入和輸出,而不是細胞生物學家解決的複雜的基本問題。因此,由臨床科學中的跨學科合作帶頭的許多快速變化的計算方法最終完全逃離了這個領域。基礎生物學不應該在小規模的機械式理解和大規模的預測之間做出選擇。它應該包含機械式建模和機器學習方法的互補優勢,以提供例如患者結果預測和疾病進展的機械式理解之間缺失的聯繫。培養在所有這些領域多才多藝的新一代研究人員對於實現這一突破至關重要。只有這樣,細胞生物學中的機械式式模型才能在
21 世紀的高通量世界中找到真正的臨床應用。 |