|
資料來源:
https://www.graphpad.com/guides/the-ultimate-guide-to-linear-regression?utm_campaign=gp%20content&utm_medium=email&utm_content=224057718&utm_source=hs_email&hsCtaTracking=2440ef28-4c24-4987-b7cc-759e00f77ae1%7C3c52e587-9ca4-4e18-98e5-6d9a24a94a00
當大多數人想到統計模型時,他們首先想到的是線性迴歸模型。大多數人沒有意識到線性迴歸是一種特定類型的迴歸。
考慮到這一點,我們將從一個整體的迴歸模型概述開始。然後在我們了解了目的之後,我們將專注於線性部分,包括為什麼它如此受歡迎,以及如何計算最佳配適迴歸線!本指南將幫助您運行和理解線性迴歸模型。它目的在為科學家和研究人員提供進修資源,並幫助新人更好地了解這個有用的建模工具。
什麼是迴歸?
在最簡單的形式中,迴歸是一種模型,它使用一個或多個變數來估計另一個變數的實際值。有很多不同類型的迴歸模型,包括最常用的線性迴歸,但它們都有共同的基礎。
通常,研究人員有一個他們有興趣預測的反應變數,以及一個或多個可以幫助做出有根據的預測變數的想法。一些簡單的例子包括:
使用年齡、膽固醇等預測因子預測疾病(如糖尿病)的進展(線性迴歸)
根據解釋變數預測生存率或死亡時間(生存分析)
根據一個人的收入水準和教育年限預測政治派別(邏輯迴歸或其他分類)
預測不同劑量的藥物抑制濃度(非線性迴歸)
迴歸有各種各樣的應用。但重點是:如果我們有一個觀察數據集,將每個項目的這些變數鏈接在一起,我們可以迴歸預測變數的反應。此外:
將模型配適到您的數據,可以告訴您一個變數如何隨著另一個變數的值變化而增加或減少。
例如,如果我們有一個包含房屋大小和售價的房屋數據集,則迴歸模型可以幫助量化兩者之間的關係。
迴歸模型最引人注目的方面是它產生的方程式。該模式給出了一條最佳配適線,在合理範圍內可用於根據預測變數的任何值生成反應變數的估計值。我們將模型的輸出稱為點估計,因為它是可能性連續體上的一個點。當然,這個預測有多好,實際上取決於從你放入模型的數據的準確性到問題的難度等。
將此與其他方法,例如相關性進行比較,相關性可以告訴您變數之間關係的強度,但對於估計反應的實際值的點估計值沒有幫助。
迴歸中的變數有什麼區別?
迴歸中有兩種不同類型的變數:一種有助於預測的預測變數(x),另一種是您試圖預測的反應值。
歷史上,預測變數在科學教科書中被稱為自變數。您可能還會看到它們被稱為x變數、迴歸量、輸入或共變數。根據迴歸模型的類型,您可以有多個預測變數,這稱為多重迴歸。預測變數可以是連續的(數值,如身高和體重)或分類的(類別或級別,如卡車/SUV/摩托車)。
用外行術語,反應變數通常解釋為“您真正想要預測或了解更多的事物”。它通常是研究的重點,可以稱為因變數、y
變數、結果或目標。一般來說,反應變數對於每個觀測值都有一個數值(例如,根據一些其他變數預測溫度),但可以有多個值(例如,預測對象為在緯度和經度上的位置)。後一種情況稱為多變數迴歸(multivariate
regression),不要與多元迴歸(multiple regression)混淆
迴歸分析的目的是什麼?
迴歸分析有兩個主要目的:
解釋性-
迴歸分析解釋了反應變數和預測變數之間的關係。例如,它可以回答諸如腎功能是否會增加某些特定疾病過程中症狀的嚴重程度之類的問題?
預測-
迴歸模型可以根據預測變數的數值給出反應變數的點估計。
我如何知道哪個模型最適合數據?
確定最佳模型的最常見方法是選擇使實際值與模型估計值之間的平變異量最小的模型。這稱為最小平方。請注意,“最小平方迴歸”通常用作線性迴歸的綽號,即使最小平方用於線性以及非線性和其他類型的迴歸。
什麼是線性迴歸?
最流行的迴歸形式是線性迴歸,它用於根據一個或多個預測變數(連續或分類)預測一個數值(連續)反應變數的值。
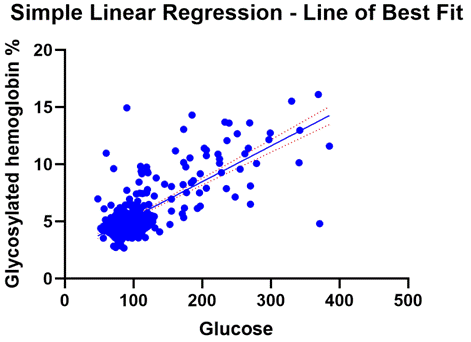
大多數人認為“線性迴歸”這個名稱來自變數之間的直線關係。對於大多數情況,這是一種直觀思考的好方法。在所有其他條件相同,隨著預測變數的增加,反應以相同的速率增加或減少。如果這種關係對於變數的任何值都成立,繪製圖形時將在數據中形成直線模式,如下例所示:
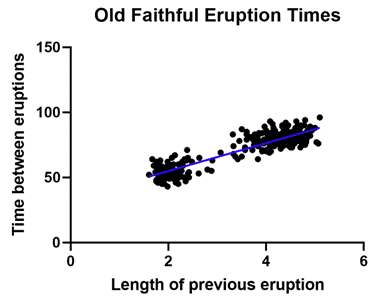
線性迴歸的實際原因是技術性的,並且具有足夠的微妙。以至於經常引起混淆。例如下圖也是線性迴歸,即使結果線是彎曲的。該定義是數學的,並且與預測變數與反應變數的關係有關。可以說線性迴歸處理最簡單的關係,但不能進行複雜的數學運算,例如將一個預測變數提高到另一個預測變數的冪次。
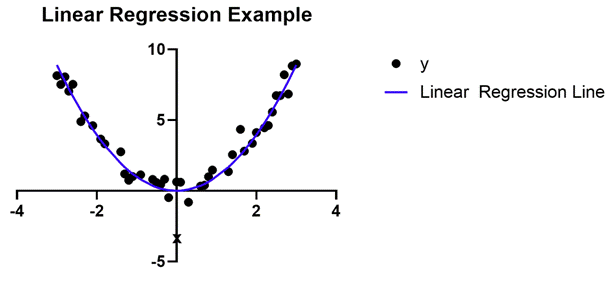
最常見的線性迴歸模型使用普通的最小平方算法來挑選模型中的參數並形成可能顯示關係的最佳線(最佳配適線)。儘管它是許多模型共享的算法,但線性迴歸是迄今為止最常見的應用。如果有人在討論最小平方迴歸,那麼他們很可能在討論線性迴歸。
線性迴歸分析的主要優點是什麼?
由於模型方程式的應用,線性迴歸模型以易於解釋而聞名。既可以用於理解潛在關係,也可以將模型應用於預測。在建模技術中,迴歸分析非常適合解釋性分析並且通常足以進行預測,這一事實很少見。
相比之下,大多數技術只做其中一種。例如,一個經過良好調整的基於人工智慧的人工神經網絡模型可能很擅長預測,但它是一個“黑匣子”,幾乎不提供可解釋性。
還有一些其他的好處:
線性迴歸的計算速度很快,尤其是在您使用統計軟體時。儘管手動完成並不總是一項簡單的任務,但它仍然比計算許多其他模型所需的時間要快得多。
迴歸模型的流行本身就是一個優勢。它是許多科學家使用的久經考驗的方法,這一事實使得協作變得容易。
線性迴歸的假設
科學家的最初反應通常是嘗試線性迴歸模型,但這並不代表著它總是正確的選擇。事實上有一些基本假設,如果被忽略,可能會使模型無效。
1.
隨機樣本-
數據中的觀察需要彼此獨立。產生相互依賴性的方式有很多種,例如,一種常見的方式是使用多重反應數據,其中多次量測單個受試者。同一個人的量測值可能是相關的,在這種情況下你不能使用線性迴歸。
2.
預測變數之間的獨立性-
如果您的模型中有多個預測變數,理論上它們不應該相互關聯。如果是這樣,這可能會導致模型配適不穩定。
3.
Homoscedasticity
-
意思是“相等的分散”,這表示您的殘差(模型預測和觀察值之間的差異)應該在連續任何地方都是均分佈的。這是使用殘差圖評估。
4.
殘差是常態分佈的。除了具有相等的分散性之外,在標準線性迴歸模型中,殘差被假定來自常態分佈。這通常使用
QQ 圖進行評估。
5.
預測變數之間的線性關係和反應-
關係必須是如上所述的線性關係,排除一些更複雜的數學關係。您可以使用變數
X 和變數 X^2(“X
平方”)作為預測變數對數據中的一些“曲線”進行建模。
6.
預測變數量測中沒有不確定性 -模型假設所有不確定性都在反應變數中。這是最細微的假設。即使您嘗試對具有自身估計的預測變數的模型進行推斷,除非您需要將不確定性歸因於預測變數。這個研究領域被稱為“量測誤差”。
有效推理的其他注意事項:
1.
代表性樣本-
您要使用的數據集應該是您嘗試推斷的母群的代表,並且是隨機的!)樣本。舉一個直觀的例子,你不應該期望所有人的行為都和你家裡的人一樣。由於我們經常低估自己的偏見,因此最好的選擇是在開始時隨機抽樣。
2.
樣本量-
如果您的數據集只有
5 個觀察值,則模型在找到真實模式方面的效率將低於具有 100
個樣本的模型。每項研究都沒有千篇一律的數字,但通常 30 或更多被認為是迴歸所需的最低值。
3.
保持在範圍內-
不要嘗試在用於建立模型的數據集範圍之外進行預測。例如,假設您正在根據平方英尺預測房屋價值。如果您的數據集只有
1,000 到 3,000 平方英尺的房屋,則該模型可能無法很好地判斷
800 或 4,000 平方英尺房屋的價值。這稱為外插,不推薦。
線性迴歸的類型
兩種最常見的迴歸類型是簡單線性迴歸和多元線性迴歸,它們的區別僅在於模型中預測變數的數量。簡單線性迴歸只有一個預測變數。
簡單線性迴歸
之所以稱為簡單是有原因的:如果您正在測試兩個連續變數(一個預測變數和一個反應變數)之間的線性關係,那麼您正在尋找一個簡單的線性迴歸模型,也稱為最小平方迴歸線。您是否希望使用更多的預測器?嘗試多元線性迴歸模型。這是兩者之間的主要區別,但也涉及其他考慮因素和差異。
解釋簡單的線性迴歸模型
還記得小學線的y = mx+b公式嗎?斜率為m
,y 截距為b
,兩者都是畫線所必需的。這也是你基本上在這裡建立的,但大多數教科書和程序都會這樣寫出迴歸的預測方程:
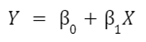
Y
是您的反應變數,X
是您的預測變數。這兩個𝛽符號稱為“參數”,模型將估計這些參數以建立您的最佳配適線。第一個(未連接到
X)是截距,另一個(X 前面的係數)稱為斜率項。
例如,我們將使用帶有糖尿病數據的示例,來自
Prism 數據集來模擬人的血糖水準(預測指標)與其糖基化血紅蛋白水準(反應)之間的關係。一旦我們運行分析,我們就會得到這個輸出:

最佳配適參數和迴歸方程式
簡單線性迴歸的 Prism
輸出的第一部分是關於模型本身的工作原理。它們可以稱為參數、估計值或(如上所述)最佳配適值。參數估計在迴歸中可能是正數或負數,具體取決於關係。
在那裡你可以看到斜率(葡萄糖)和 y
軸截距。這些值有助於我們建立模型用於估計和預測的方程:
糖基化血紅蛋白 = 2.24 +
(0.0312*葡萄糖)
使用這個等式,我們可以在我們的數據集範圍內插入任何數字以獲取葡萄糖,並估計該人的糖基化血紅蛋白水準。例如,90
的葡萄糖水準對應於該人的糖基化血紅蛋白水準的估計值 5.048。但這只是如何使用這些參數的開始。
解釋參數估計
您也可以自己解釋簡單線性迴歸的參數,因為只有兩個,所以非常簡單。
斜率參數通常最有幫助:這代表著葡萄糖每增加
1 個單位,估計的糖基化血紅蛋白水準將增加 0.0312
個單位。順便說一句,如果它是負數(可能是 -0.04),我們會說葡萄糖增加
1 個單位實際上會使估計的反應降低 -0.04。
截距參數對於配適模型很有用,因為它會向上或向下移動最佳配適線。在此示例中,它顯示的值 (2.24)
是葡萄糖水準為 0
的人的預測糖基化血紅蛋白水準。在這種情況下,截距的解釋不是很有趣或有用。
簡單地說,如果數據集中沒有值為 0
的預測變數,則應忽略這部分解釋,將模型視為一個整體和斜率。但是,請注意,如果您將一個人的葡萄糖插入
0,則 2.24 正是完整模型估計的值。
信賴區間和標準誤差
回到了沒有模型是完美的核心。今天可以對最佳配適參數給出“點估計”,但在試圖找到變數之間真實和準確的關係時,仍然存在一些不確定性。
標準誤差和信賴區間共同作用以估計該不確定性。從估計中添加和減去標準誤差,以獲得該真實關係的合理範圍的可能值。有了這個
95% 的信賴區間,您可以說您相信該參數的真實值介於兩個端點之間(對於葡萄糖的斜率,介於
0.0285 和 0.0340 之間)。
這種方法起初可能看起來過於謹慎,但只是給出了圍繞點估計的一系列真實可能性。畢竟,您不想知道您給出的點估計值是否變化很大嗎?這給了你那個缺失的部分。
配適度
可以通過圖形和數字方式確定模型的配適程度。如果您知道要查找什麼,沒有什麼比繪製數據來評估配適,以及您的數據滿足模型假設的程度更好的了。這些診斷圖形繪製了殘差,即估計模型和觀察到的數據點之間的差異。
一個好的圖是殘差圖與預測變數 (X)
的關係。在這裡,您要尋找相等的散佈點,這代表著點在所有 x
值的虛線上方和下方都大致相同。左邊的圖看起來很棒,而右邊的圖顯示出明顯的拋物線形趨勢,需要解決。
評估配適優良程度的另一種方法是使用 R
平方統計量,它是模型解釋的反應中變異量的比例。在這種情況下,0.561
的值表示糖基化血紅蛋白的 56%
的變異可以用這個非常簡單的模型方程式(實際上是那個人的葡萄糖水準)來解釋。
R-squared
這個名字可能會讓你想起一個類似的統計數據:Pearson's
R,它衡量任何兩個變數之間的相關性。有趣的事實:只要你在做簡單的線性迴歸,R-squared
的平方根(也就是 R)就相當於預測變數和反應變數之間的
Pearson's R 相關性。
原因是簡單的線性迴歸利用了與
Pearson's R 相關性相同的最小平方機制。請記住,雖然迴歸和相關是相似的,但它們並不是同一回事。差異通常歸結為分析的目的,因為相關性不符合數據點的一條線。
顯著性和 F 檢驗
所以我們有一個模型,我們知道如何使用它進行預測。我們知道
R 平方可以了解模型與數據的配適程度。但我們如何知道變數之間是否真的存在顯著關係?
底部的部分提出了同樣的問題:斜率是否顯著非零?這對於這個模型尤其重要,其中最佳配適值(大約 0.03)在肉眼看來非常接近
0。我們如何以一種或另一種方式感到自信?
在這種情況下,斜率明顯非零:F
檢驗給出的 p 值小於 0.0001。
F 檢驗為整個模型而不是其單個斜率回答了這個問題,但在這種情況下,無論如何只有一個斜率。 P
值總是被解釋為與“顯著性臨界值”相比:如果它小於臨界值水準,則稱該模型顯示出與“無關係”(或零假設)顯著不同的趨勢。根據我們如何設置迴歸分析以使用
0.05 作為顯著性臨界值,它告訴我們模型指向顯著關係。有證據表明這種關係是真實的。
如果不是,那麼我們實際上是在說沒有證據表明該模型提供了隨機猜測之外的任何新資訊。換句話說:模型可能會為預測輸出一個數字,但如果斜率不顯著,則實際上可能不值得考慮該預測。
繪製線性迴歸
由於線性迴歸模型會生成直線方程式,因此繪製線性迴歸與點本身相關的最佳配適線,是查看模型與眼睛測試的配適程度的常用方法。像
Prism 這樣的軟體使迴歸的繪圖部分變得異常簡單,因為圖形是與模型的細節一起自動建立的。以下是更多繪圖技巧,以及我們分析中的一個示例:
多元線性迴歸
如果您了解簡單線性迴歸的基礎知識,那麼您也了解大約
80%
的多元線性迴歸。內部工作原理是一樣的,它仍然基於最小平方迴歸計算法,它仍然是一個目的在預測反應的模型。但是,多元線性迴歸不僅僅使用一個預測變數,而是使用多個預測變數。
模型方程與前一個相似,您注意到的主要是它更長,因為有額外的預測變數。假設您正在使用 3
個預測變數,預測方程將產生 3 個斜率估計(每個一個)以及一個截距項:
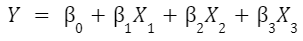
Prism
可以輕鬆建立多元線性迴歸模型,尤其是計算迴歸斜率係數和生成圖形以診斷模型的配適程度。
關於多重共線性,我需要了解什麼?
這裡討論了多元線性迴歸的假設。對於多個預測變數,除了解釋變得更具挑戰性之外,另一個增加的複雜性是多重共線性。
當兩個或多個預測變數在它們量測的內容中“重疊”時,就會出現多重共線性。在其他地方,您會看到這被稱為變數相互依賴。理想情況下,預測變數是獨立的,沒有一個預測變數會影響另一個變數的值。
有多種評估多重共線性的方法,但要知道的主要事情是多重共線性不會影響您的模型預測點值的程度。然而,它混淆了關於每個單獨變數如何影響反應的推斷。
例如,假設您要估算一棵樹的高度,並且您在距地面兩個高度(一米和兩米)處量測了樹的周長。周長將高度相關。如果將兩者都包含在模型中,則很可能最終會得到其中一個圓周的負斜率參數。顯然,當周長變大時,樹並不會變短。相反,該負斜率係數充當對另一個變數的調整。
簡單線性迴歸和多元線性迴歸有什麼區別?
一旦您確定您的研究非常適合線性模型,兩者之間的選擇就歸結為您包含多少預測變數。只有一個?簡單的線性。比那更多的?多重線性。
基於如此,您可能想知道,“當多元線性迴歸可以解釋更多變數時,為什麼我還要進行簡單的線性迴歸呢?”好問題!
答案是有時少即是多。一個常見的誤解是模型的目標是
100%
準確。科學家們知道,沒有完美的模型,它是現實的簡化版本。所以目標不是完美。相反,目標是找到一個盡可能簡單的模型來描述關係,以便您了解系統、得出有效的科學結論並設計新的實驗。
還是不服氣?假設您能夠為數據集中的每個點建立一個
100% 準確的模型。大多數情況下,如果你這樣做了,你就做了以下兩件事之一:
1.
得出一個沒有實際用處的明顯結論(100% 獲勝的籃球隊得分高於對手)或
2.
您不僅對數據中的趨勢進行了建模,而且還對因多變化而無法指望的隨機“噪聲”進行了建模。這被稱為“過度配適”:你努力解釋過去的各個方面,以至於模型忽略了未來會出現的差異。
其他差異出現在技術方面。舉一些簡單的例子,使用多元線性迴歸代表著:
1.除了模型的整體解釋和意義之外,現在每個斜率都有自己的解釋和意義問題。
2.R-squared
不像簡單的線性迴歸那樣直觀。
3.繪製方程不再是一條線。您可以說多元線性迴歸並不適合繪製圖表。
總而言之:簡單迴歸總是比多元線性迴歸更直觀!
解釋多元線性迴歸
我們已經說過,多元線性迴歸比簡單線性迴歸更難解釋,這是真的。排除數學和更多技術方面的問題,涉及的因素越多,整體解釋總是越難。但是,雖然有更多的事情需要跟踪,但思維過程的基本組成部分保持不變:參數、信賴區間和顯著性。我們甚至以同樣的方式使用模型方程。
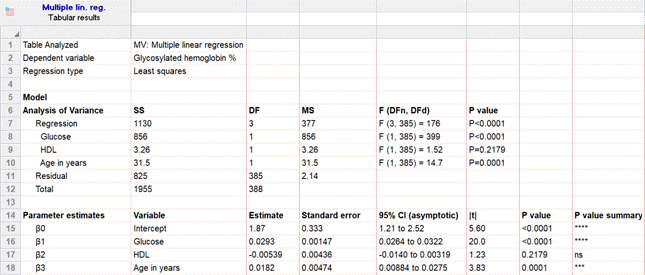
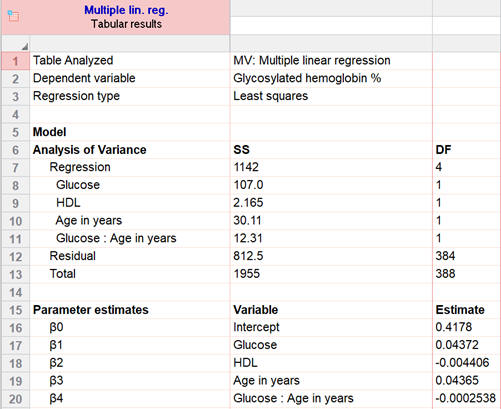
讓我們使用相同的糖尿病數據集來說明,但有一個新的問題:除了葡萄糖水準之外,我們還將包括 HDL
和人的年齡作為其糖基化血紅蛋白水準(反應)的預測因子。這是 Prism
的輸出:
變異量分析和 F 檢驗
雖然大多數科學家的眼睛直接進入參數估計部分,但輸出的第一部分很有價值,是最好的起點。變異量分析將模型作為一個整體(以及一些單獨的部分)進行測試,以在您理解其餘部分之前告訴您您的模型有多好。
它包括平方和表,該部分最右側的 F
檢驗是最受關注的。 “迴歸”作為一個整體(在該部分的第一行)具有小於
0.0001 的 p 值,並且在我們選擇使用的
0.05 水準上是顯著的。每個參數斜率也有自己單獨的 F 檢驗,但作為
t 檢驗更容易理解。
參數估計和 T 檢驗
現在是有趣的部分:模型本身俱有我們用於簡單線性迴歸的相同結構和資訊,我們對它的解釋非常相似。關鍵是要記住,您是在單獨解釋每個參數,而不是您必須記住一個參數!。
Prism 將每個參數的所有統計資訊放在一個表中,包括(對於每個參數):
1.參數的估計本身
2.它的標準誤差和信賴區間
3.來自
t 檢驗的 P 值
估計本身很簡單,用於製作模型方程,就像以前一樣。在這種情況下,模型的預測方程是(四捨五入到最接近的千分之一時):
糖基化血紅蛋白 = 1.870 +
0.029*葡萄糖 - 0.005*HDL +0.018*年齡
如果你還記得我們簡單的線性迴歸模型,葡萄糖的斜率發生了輕微的變化。那是因為我們現在也在考慮其他因素。這種區別有時會極大地改變對單個預測變數影響的解釋。
在解釋預測變數的單個斜率估計值時,差異可以追溯到多重迴歸如何假設每個預測變數獨立於其他變數。對於簡單的迴歸,您可以說“X
增加 1 點通常對應於 Y
增加 5 點”。對於多元迴歸,它更像是“假設所有其他因素都相等,X
增加 1 點通常對應於 Y
增加 5 點。”這似乎不是一個很大的飛躍,但它承認
1) 有更多的因素在起作用,以及 2)
需要這些預測變數不會對彼此產生影響,以使模型有所幫助。
還顯示了每個參數的標準誤差和信賴區間,從而單獨了解每個斜率/截距的可變性。解釋這些中的每一個的方式與我們在簡單線性迴歸示例中提到的方式完全相同,但請記住如果存在多重共線性,則標準誤差和信賴區間會被誇大,而且通常是劇烈的。
最後是 p
值,正如您可能猜到的那樣,它的解釋就像我們對第一個示例所做的那樣。這裡 p
值背後的基礎方法是 t
檢驗。這些僅說明每個因素的重要性,要從整體上評估模型,我們需要在頂部使用 F 檢驗。
儘管單獨評估每個因素仍然有幫助:在這種情況下,它表明雖然其他預測變數都很重要,但
HDL
沒有任何意義,因為我們已經考慮了其他因素。這並不是說它本身沒有任何意義,只是它沒有為僅包含葡萄糖和年齡的模型增加任何價值。事實上,既然我們知道了這一點,我們可以選擇只用葡萄糖和年齡重新運作我們的模型,並為那個更簡單的模型輸入更好的參數估計。
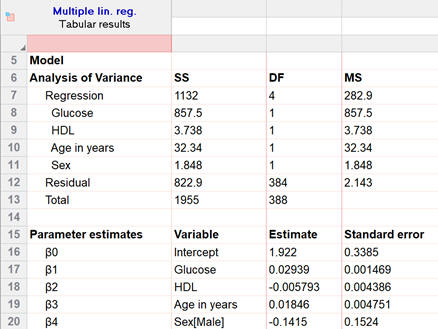
當您在我們的示例數據中具有諸如性別之類的分類預測變數時,就會出現另一個解釋差異。當您向模型添加分類變數時,您選擇了一個“參考水準”。在這種情況下(下圖),我們選擇女性作為我們的參考水準。下面的模型表明,男性的預測反應略低於女性(約低
0.15)。
配適程度
評估你的模型與多元線性迴歸的配適程度比簡單線性迴歸更困難,儘管想法保持不變,即有圖形和數字診斷。
至少,最好檢查殘差與預測圖以尋找趨勢。在我們的糖尿病模型中,這個圖(包括在下面)起初看起來不錯,但有一些問題。請注意,值往往會在左側偏高而在右側偏低。
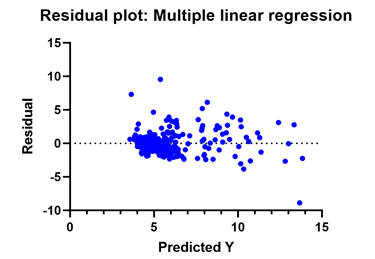
但是,在進一步檢查時,請注意只有少數離群點會導致這種不均勻的分散。如果您在分析中看到上述異常值會破壞等式分散,那麼您有幾個選擇。
至於配適優良度的數值評估,多元線性迴歸有更多選擇。如果您只想要一個度量來描述模型解釋的反應變數中的變異量比例,R
平方仍然是首選。然而,配適優良度統計的一個常見用途是執行模型選擇,這代表著決定模型中包含哪些變數。如果這就是您使用配適優良度的目的,那麼您最好使用調整後的
R 平方或 AICc 等資訊標準。
繪製多元線性迴歸
圖表對於測試多元線性迴歸模型的整體配適程度非常有用。對於多個預測變數,將預測變數與反應變數繪製成圖是不可行的,就像在簡單的線性迴歸中一樣。一個簡單的解決方案是使用
x 軸上的預測反應值和 y
軸上的殘差(如上所示)。提醒一下,殘差是預測反應值和觀察反應值之間的差異。還有其他幾個使用殘差的圖可用於評估其他模型假設,例如常態分佈誤差項和序列相關性。
模型選擇 - 選擇要包含的預測變數
您如何知道要在模型中包含哪些預測變數?這是一個很好的問題,也是一個活躍的研究領域。
對於大多數科學領域的研究人員來說,您正在處理一些預測變數,並且您對模型的一般結構有一個很好的假設。如果是這種情況,那麼您可能只是嘗試配適幾個不同的模型,然後根據殘差的外觀選擇看起來最好的模型,並使用配適優度指標,例如調整後的
R-square或AICc
。
為什麼我的模型不適合?
有很多原因會導致您的模型不適合。原因之一是反應中有太多無法解釋的差異。這可能是因為存在您未量測的重要預測變數,或者預測變數與反應之間的關係比簡單的線性迴歸模型更複雜。在最後一種情況下,您可以考慮使用預測變數的交互項或變換。
如果預測準確性對您來說很重要,這代表著您只需要對反應進行良好估計而不需要了解預測變數如何影響它,那麼有很多聰明的計算工具可用於建立和選擇模型。
交互效應
交互效應和轉換是解決僅使用未修改的預測變數不能很好地配適模型的情況的有用工具。
通過將兩個預測變數相乘以建立一個新的“交互”變數來找到交互項。它們極大地增加了描述每個變數如何影響反應的複雜性。主要用途是允許更大的靈活性,以便一個預測變數的影響取決於另一個預測變數的值。
對於使用上述糖尿病數據的具體示例,也許我們有理由相信葡萄糖對反應(血紅蛋白百分比)的影響會根據患者的年齡而變化。
Stats 軟體使這變得簡單,但實際上,我們將葡萄糖乘以年齡,並在我們的模型中包含這個新術語。四捨五入時我們的新模型是:
糖基化血紅蛋白 = 0.42 +
0.044*葡萄糖 - 0.004*HDL +0.044*年齡
- 0.0003*葡萄糖*年齡
作為參考,我們沒有交互項的模型是:
糖基化血紅蛋白 = 1.865 +
0.029*葡萄糖 - 0.005*HDL +0.018*年齡
添加交互項會大大改變其他估計!解釋這代表著什麼是具有挑戰性的。至少,我們可以說葡萄糖的影響取決於這個模型的年齡,因為這些係數在統計上是顯著的。我們可能還想說,由於交互項的負係數估計
(-0.0002),高血糖對老年患者的影響似乎較小。但是該模型(以及幾乎所有具有交互項的模型)中存在非常高的多重共線性,因此應謹慎解釋係數。即使在這個例子中,如果我們刪除一些異常值,這個交互項在統計上不再顯著,所以它是不穩定的,可能只是噪聲數據的副產品。
轉換
除了交互之外,當您的模型不能很好地配適您的數據時使用的另一種策略是變數的轉換。您可以轉換您的反應或任何預測變數。
對反應變數的轉換相當大地改變了解釋。它不是配適您的反應變數y的模型,而是配適轉換後的y
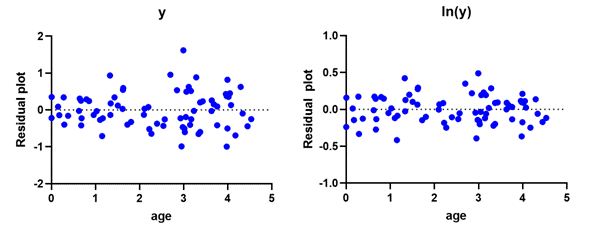
。一個適用的常見示例是預測動物物種不同年齡的身高。由於出生時身高的變異性非常小,但成年動物的身高變異性要高得多,因此使用了對反應(在這種情況下為身高)的對數轉換。這違反了等分散的假設。
在下面的圖中,請注意左側的漏斗型形狀,隨著年齡的增長,散點會變寬。在右側,漏斗形狀消失了,殘差的可變性看起來一致。
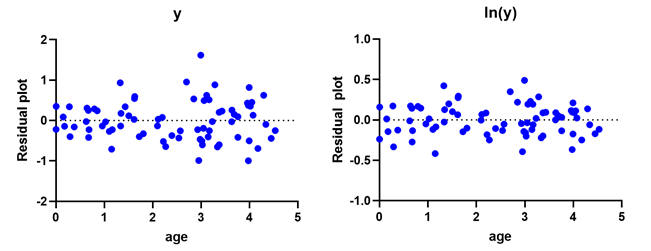
使用對數轉換 y
的線性模型配適得更好,但是現在模型的解釋發生了變化。使用上面的示例數據,預測模型為:
ln(y) = -0.4 + 0.2 * x
這代表著x的單個單位變化會導致y的對數增加
0.2 。這對大多數人來說意義不大。相反,您可能希望您的解釋在原始y尺度上。為此,我們需要對等式兩邊取冪次,這(避免數學細節)代表著
x 增加 1 個單位會導致y增加
22% 。
所有這一切都是說轉換可以幫助配適您的模型,但它們會使解釋複雜化。
當線性迴歸沒作用時
線性迴歸的普遍存在對研究合作有利,但有時它會導致研究人員假設線性迴歸模型是適用於各種情況的正確模型。有時,軟體甚至似乎強化了這種態度和隨後選擇的模型,而不是繼續控制他們研究的人。
當然,線性迴歸因其簡單性和熟悉性而非常有用,但在許多情況下有更好的選擇。
其他類型的迴歸
邏輯迴歸
線性與邏輯迴歸:當您的反應變數是連續的時,線性迴歸是合適的,但如果您的反應只有兩個級別(例如,存在/不存在、是/否等),那麼請查看簡單邏輯迴歸或多元邏輯迴歸。
普瓦松迴歸
相反,如果您的反應變數是一個計數(例如,一個地區的地震次數、雌性鱟附近築巢的雄性數量等),那麼請考慮普瓦松迴歸。
非線性迴歸
對於預測變數和反應變數之間更複雜的數學關係,例如藥代動力學中的劑量反應曲線,請查看非線性迴歸。
變異量分析
如果您設計並運行了一個具有連續反應變數的實驗,並且您的研究因素是分類的(例如,飲食 1/飲食
2、治療 1/治療 2
等),那麼您需要 ANOVA 模型。這些通過處理次數(單向變異量分析、雙向變異量分析、三向變異量分析)或其他特徵(例如重複量測變異量分析)來區分。
主成分迴歸
主成分迴歸很有用。它提供了一種降低預測變數“維度”的技術,因此您仍然可以配適線性迴歸模型。
Cox
比例風險迴歸
Cox
比例風險迴歸是生存分析的首選技術,當您有數據量測事件發生前的時間時。
戴明迴歸
當有兩個變數( x和y
)並且兩個變數都存在量測誤差時,戴明迴歸很有用。發生這種情況的一種常見情況是比較兩種不同方法的結果(例如,比較量測血氧水準或檢查特定病原體的兩台不同機器)。 |