|
資料來源:
https://www.datapine.com/blog/misleading-statistics-and-data/
目錄
(1)
什麼是誤導性統計數據?
(2)統計數據可靠嗎?
(3)現實生活中的誤導性統計示例
(4)
統計數據如何具有誤導性
(5)
如何避免和識別濫用統計數據?
在歷史上,統計分析一直是高科技和先進商業行業的支柱,如今它們比以往任何時候都更加重要。隨著先進技術和全球化營運的興起,統計分析使企業能夠洞察與解決市場的極端不確定性。促進了明智的研究決策、合理的判斷和基於證據而非假設的行動。
由於企業經常被迫遵循難以解釋的市場路線圖,因此統計方法可以幫助制定必要的規劃,以應對充滿坑洼、陷阱和敵對競爭的環境。統計研究還有助於商品或服務的營銷,以及了解每個目標市場的獨特價值驅動因素。在數字時代,只有通過實施先進技術和商業智慧軟體,才能進一步增強和利用這些能力。如果這一切都是真的,那麼統計數據有什麼問題?
實際上,統計數據因其作為誤導性和不良數據存在的能力和潛力而臭名昭彰。為了開始這個旅程,讓我們看一下誤導性的統計定義。
什麼是誤導性統計數據?
誤導性統計數據是指故意或錯誤地濫用數字數據。結果提供了欺騙性資訊,這些資訊會圍繞某個主題建立虛假敘述。統計數據的濫用經常發生在廣告、政治、新聞、媒體和其他領域。
由於數據在當今快速發展的數字世界中的重要性,熟悉誤導性統計和監督的基礎知識非常重要。作為盡職調查的練習,此將回顧一些最常見的濫用統計數據的形式,以及來自公共生活的各種令人震驚,遺憾的是常見的誤導性統計數據示例。
統計數據可靠嗎?
73.6%
的統計數據是錯誤的。真的嗎?不,當然,這是一個虛構的數字。儘管這樣的研究會很有趣,但同樣,它可能同時試圖指出所有的缺陷。統計可靠性對於確保分析的準確性和有效性十分重要。為了確保高可靠性,需要執行各種技術,其中第一個是控制測試。在類似條件下重現實驗,應該有類似的結果。這些控制措施是必不可少的,應該成為任何實驗或調查的一部分。不幸的是,情況並非總是如此。
雖然數字不會說謊,但實際上它們可以用來誤導半真半假的事實。這被稱為“濫用統計數據”。人們通常認為,統計數據的濫用僅限於那些試圖從歪曲事實中獲利的個人或公司,無論是經濟、教育還是大眾媒體。
然而,通過研究說出半真半假的方法不僅限於數學愛好者。愛丁堡大學Daniele
Fanelli博士 2009 年的一項調查發現。
33.7% 的接受調查的科學家承認有問題的研究作業,包括修改結果以改善結果、主觀數據解釋、隱瞞分析細節以及因直覺而放棄觀察,唉!.科學家們!
雖然數字並不總是必須捏造或誤導,但很明顯,即使是社會上最值得信賴的數字守門人也不能倖免於統計解釋過程中可能出現的粗心和偏見。統計數據有多種誤導方式,將在後面詳細介紹。最常見的當然是相關性與因果關係。它總是會遺漏另一個(或兩個或三個)因素,這些因素是問題的實際原因。喝茶會使糖尿病增加50%,禿頂增加心血管疾病風險高達70%!我們是否忘記提及茶中的糖分含量或禿頂與老年相關的事實,就像心血管疾病風險和老年一樣?
那麼,統計數據可以被操縱嗎?他們肯定可以。數字會撒謊嗎?你可以判斷。
現實生活中的誤導性統計示例
既然我們已經將統計數據的濫用置於此文中,讓我們看一下在五個不同但相關的範圍內,具有誤導性的各種數字時代統計示例:媒體和政治、新聞、廣告、科學和醫療保健。雖然此處列出的某些主題可能會根據個人的觀點激起情感,但它們的包含僅用於數據演示目的。
(1) 媒體和政治中誤導性統計數據的例子
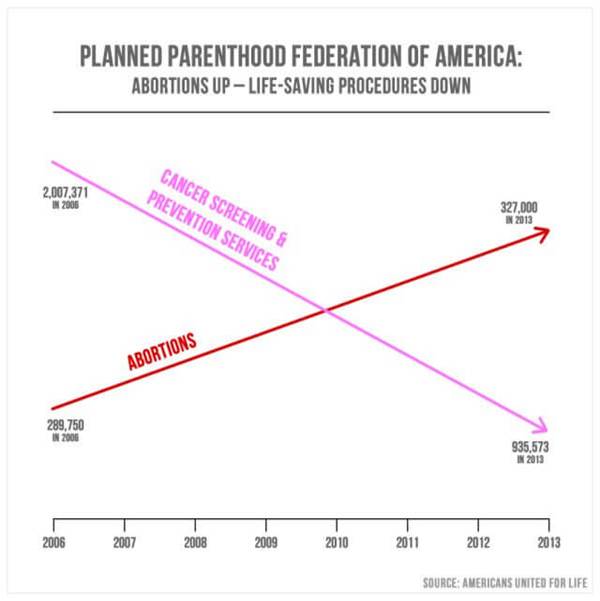
媒體中的誤導性統計數據很常見。
2015 年 9 月 29
日,美國國會共和黨人就美國計劃生育協會主席Cecile Richards挪用
5 億美元年度聯邦資金一事,向其提出質疑。上述圖表/圖表是作為重點介紹的。
代表 Jason
Chaffetz解釋說:“粉紅色表示乳房檢查的減少,紅色表示流產的增加。這就是你的組織中正在發生的事情。”
根據圖表的結構,它實際上似乎表明自
2006 年以來墮胎數量大幅增長,而癌症篩查數量大幅下降。目的是傳達從癌症篩查到墮胎的重點轉移。圖表點似乎表明
327,000 次墮胎的內在價值高於 935,573
次癌症篩查。然而,仔細檢查會發現圖表沒有定義的 y
軸。這代表著對於可見量測線的放置沒有明確的理由。
Politifact是一個事實核查倡導網站,通過與計劃生育自己的年度報告進行比較,審查了Rep.
Chaffetz 的數字。使用明確定義的比例,資訊如下所示:
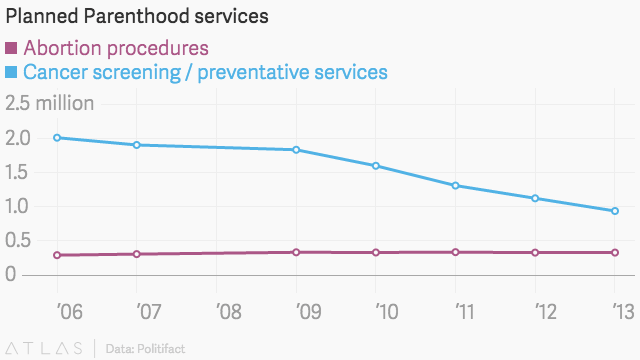
像這樣使用另一個有效的比例:
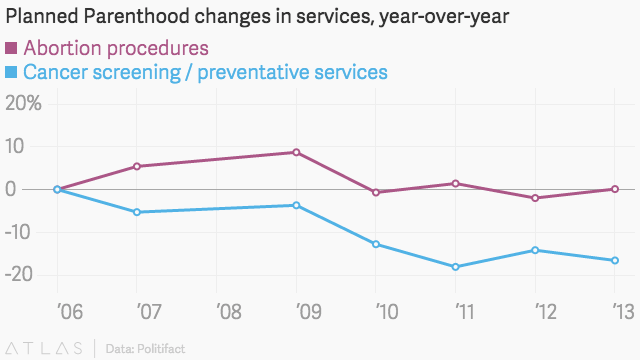
一旦放在一個明確定義的範圍內,很明顯,雖然癌症篩查的數量實際上已經減少,但它仍然遠遠超過每年進行的墮胎手術的數量。因此這是一個很大的誤導性統計示例,考慮到該圖表並非來自國會議員,而是來自反墮胎組織
American United for Life。有些人可能會認為存在偏見。這只是媒體和政治中誤導性統計數據的眾多例子之一。
(2) 醫療保健中的誤導性統計示例
如果沒有醫療保健行業的案例,這份誤導性統計謬誤列表將不完整。隨著
COVID-19
大流行,公眾被迫以數據可視化的形式消費科學資訊,以隨時了解病毒的當前發展。但這並不容易。公眾缺乏統計知識,加上組織並不總是共享準確的統計資訊,導致數據的虛假陳述普遍存在。
Christopher Engledowl和
Travis Weiland 撰寫了一篇富有洞察力的文章,名為“數據錯誤表示和COVID
-19:利用誤導性數據可視化來提高 6-16 年級的統計素養”。在這裡,他們談到了以誤導方式使用
COVID-19 數據的兩個用例。讓我們仔細看看其中之一。
2020
年 5 月,在
COVID-19 開始在世界傳播大約 5
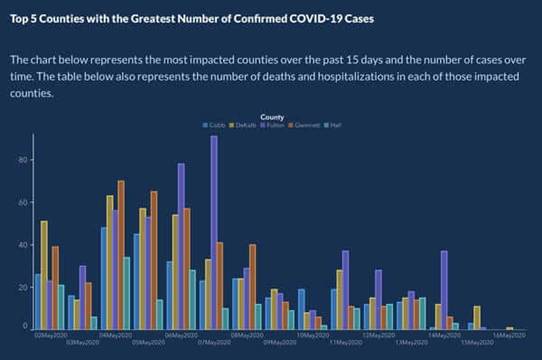
個月後,美國喬治亞州公共衛生部發布了一張圖表,目的在顯示過去 15 天內
COVID-19 病例數最高的 5 個 和隨著時間的推移案件數量。
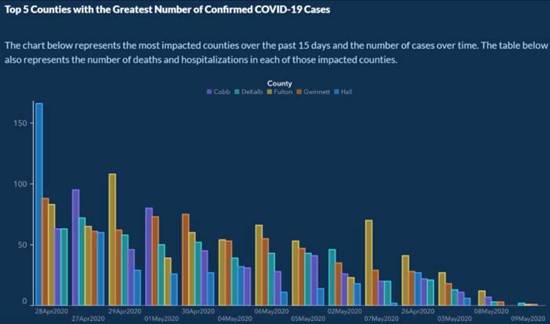
資料來源:
Vox
現在,如果我們仔細查看這張圖表,我們會發現一些錯誤,這些錯誤會使資訊非常具有誤導性。首先,X
軸沒有標籤,即使根據圖表,它是為了顯示一段時間內的病例數,這不會發生。
另一個問題,也許是所有問題中最糟糕的,是條形下方的日期沒有按時間順序排列。相反,我們看到 4
月和 5
月之間的日期穿插,目的是讓該圖表的查看者相信病例正在逐漸減少。這與郡並不總是以相同的順序描述,而是以案件的降序排列的事實相結合。這樣做的目的是讓案件看起來正在下降。
該圖表在社交媒體上引起了很大爭議,尤其是在
Twitter 上,用戶指出喬治亞州衛生部在 COVID-19
爆發期間一再使用誤導性統計數據。作為對這個問題的回答,喬治亞州州長的通訊主管Candice
Broce 。 Brian Kemp 說:“x
軸的設置方式是顯示遞減值,以便更容易地顯示這些日期的峰值和郡,我們的任務失敗了。我們道歉。它已修復”。該圖表後來以有組織的日期和郡重新發布。您可以在下面看到更新的版本。
資料來源:商業內幕
這是醫療保健領域誤導性統計數據的眾多有爭議的例子之一,它說明了當局有責任準確告知其受眾。在全球大流行等危急情況下,這一點變得更加重要,因為錯誤資訊可能導致更大的傳播和更多的死亡。為了避免這種情況,有很多醫療保健分析軟體可以幫助分析師和普通用戶,為他們的數據建立令人驚嘆和準確的可視化。
(3) 廣告中的誤導性統計數據

接下來,在我們的不良統計示例列表中,我們有一個流行的牙膏品牌的案例。
2007 年,高露潔被英國廣告標準局 (ASA) 下令放棄他們的廣告主張:“超過
80% 的牙醫推薦高露潔。”有問題的口號被放置在英國的廣告牌上,被認為違反了英國的廣告規則。
該聲明基於製造商對牙醫和衛生師進行的調查,但被發現具有失實性,因為它允許參與者選擇一種或多種牙膏品牌。
ASA 表示,這一說法“讀者會理解為,80%
的牙醫推薦高露潔超過其他品牌,剩下的 20% 會推薦不同的品牌。”
ASA
繼續說道,“因為我們了解到接受調查的牙醫對另一個競爭對手的品牌的推薦幾乎與高露潔品牌一樣多。我們得出的結論是,該聲明誤導性地暗示了
80% 的牙醫,推薦高露潔牙膏優於所有其他品牌。” ASA
還聲稱,用於調查的腳本告知參與者,該研究是由一家獨立研究公司進行的,這本質上是錯誤的。
根據我們介紹的濫用技術,可以肯定地說,高露潔的這種花招是廣告中誤導性統計數據的一個明顯例子,並且會受到錯誤的民意調查和完全的偏見。
(4) 新聞中的誤導性統計示例
濫用統計數據無處不在,新聞媒體也不例外。多年來,美國Fox新聞網因展示誤導性統計圖表而多次受到審查,這些圖表似乎故意描繪了一個不準確的結論。最近的一個案例發生在幾個月前的
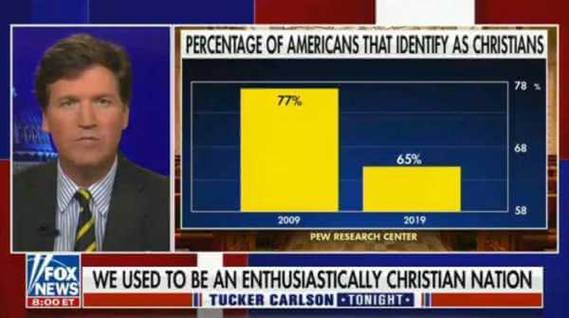
2021 年 9 月。主播Tucker
Carlson展示了一張圖表,顯示在過去十年中,被認定為基督徒的美國人數量急劇下降。
資料來源:www.rawstory.com
在上圖中,我們可以看到在
2009 年的圖表77% 的美國人為基督徒,這個數字在
2019 年下降到 65%。現在如果這裡的問題不夠明顯,我們可以看到圖中的
Y 軸圖表從 58% 開始,到 78%
結束。這使得從 2009 年到 2019
年的 12% 下降看起來比實際要重要得多。
如前所述,這並不是Fox新聞唯一一次因為這些情況而受到批評。媒體濫用統計數據的例子非常普遍。哥倫比亞新聞學院教授Bill
Grueskin甚至給學生上了一堂關於這個話題的課,並使用美國新聞節目中的幾張誤導性圖表作為展示數據時不該做什麼的例子。
Grueskin在Twitter
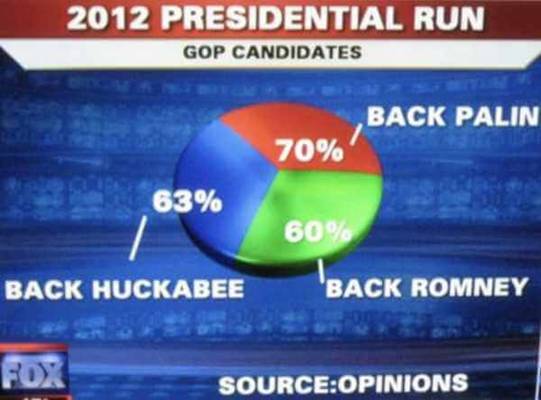
線上課程中分享了其中一些富有洞察力的誤導性統計示例,該線程變得非常流行。我們拿了一個非常明顯的給你看。對於
2012 年的總統競選,新聞網路顯示了下圖,我們看到一個餅圖顯示總數為 193%,這顯然是錯誤和誤導的,因為總數應該是
100%。
資料來源:比爾·格魯斯金
(5)科學中的誤導性統計數據
就像墮胎一樣,全球暖化是另一個可能引發情緒的政治話題。這也恰好是反對者和支持者通過研究大力支持的話題。讓我們來看看一些支持和反對的證據。
人們普遍認為,1998
年全球平均氣溫為 58.3 F。這是根據NASA’s
Goddard Institute for Space Studies的說法。
2012年,全球平均氣溫測得58.2 F。因此,全球變暖的反對者認為,由於全球平均氣溫在
14 年期間下降了 0.1 F,全球變暖是不成立的。
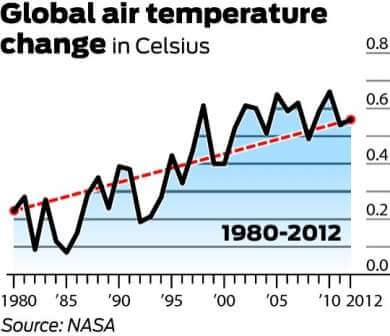
下圖是最常被引用來反駁全球變暖的圖表。它展示了從
1998 年到 2012 年的氣溫(℃)變化。
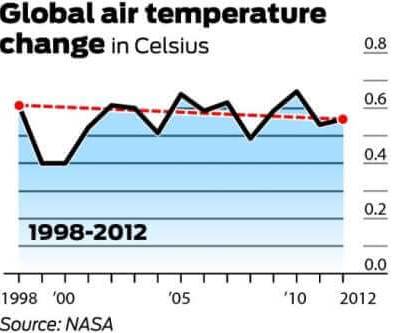
值得一提的是,由於異常強烈的厄爾尼諾風流,1998
年是有記錄以來最熱的年份之一。還值得注意的是,由於氣候系統內部存在很大程度的可變性,溫度通常以至少
30 年的周期進行量測。下圖顯示了 30 年來全球平均氣溫的變化。
現在看看從
1900 年到 2012 年的趨勢:
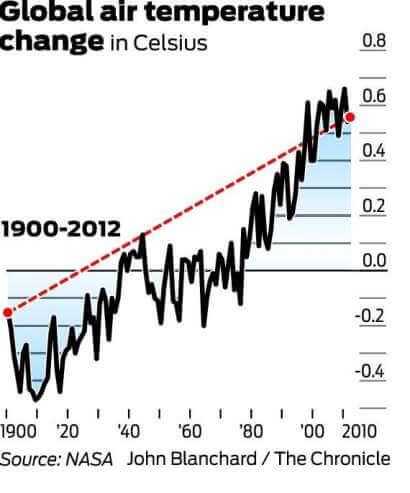
雖然長期數據似乎反映了一個高原,但它清楚地描繪了一幅逐漸變暖的圖景。因此,使用第一張圖,並且僅使用第一張圖來反駁全球變暖是一個完美的誤導性統計示例。
統計數據如何誤導

請記住,濫用統計數據可能是偶然的,也可能是有目的的。雖然用誤導性統計數據模糊界限的惡意意圖,肯定會放大偏見,但這種意圖並不是製造誤解的必要手段。統計數據的濫用是一個更廣泛的問題,現在滲透到多個行業和研究領域。以下是一些通常會導致誤用的潛在事故:
(1)
詢問錯誤
表達問題的方式會對觀眾回答問題的方式產生巨大影響。特定的措辭模式具有說服力,並促使受訪者以可預測的方式回答。例如,在一項尋求稅務意見的民意調查中,讓我們看看兩個潛在的問題:
-
你認為你應該被徵稅,這樣其他公民就不必工作了嗎?
-
你認為政府應該幫助那些找不到工作的人嗎?
這兩個問題可能會引起截然不同的反應,儘管它們涉及的是同一個主題的政府援助。這些是“加載問題”的示例。
一個更準確的措辭是,“你支持政府的失業援助計劃嗎?”或者,(更中立的)“你對失業援助有什麼看法?”
原始問題的後兩個示例消除了投票者的任何推論或建議,因此更加公正。另一種不公平的投票方式是提出一個問題,但在其前面加上條件陳述或事實陳述。繼續我們的例子,它看起來像這樣:“由於中產階級的成本上升,你支持政府援助計劃嗎?”
一個好的經驗法則是始終對民意調查持保留態度,並嘗試審查實際提出的問題。它們提供了很好的洞察力,通常比答案更重要。
(2)
有缺陷的相關性
相關性的問題在於:如果你量測了足夠多的,最終會發現其中一些是相關的。由於沒有任何直接相關性,二十分之一的人將不可避免地被認為是重要的,因此可以操縱研究(使用足夠的數據)來證明不存在的相關性或不足以證明因果關係的相關性。
為了進一步說明這一點,讓我們假設一項研究發現,紐約州
6 月 (A) 月份的車禍增加與六月
(B)紐約州熊襲擊事件的增加之間存在相關性。。
這代表著可能會有六種可能的解釋:
-
車禍(A)導致熊襲擊(B)
-
熊攻擊(B)導致車禍(A)
-
車禍 (A)
和熊襲擊 (B) 部分相互導致
-
車禍(A)和熊襲擊(B)是由第三因素(C)引起的
-
熊攻擊 (B)
是由與車禍 (A) 相關的第三個因素 (C)
引起的
-
相關性只是機會
任何明智的人都會很容易地識別出車禍不會導致熊襲擊的事實。每個都可能是第三個因素的結果,即:由於 6
月份的旅遊旺季,人口增加。說它們是相互引起的,那將是荒謬的。這正是為什麼它是我們的例子。很容易看出相關性。
但是,因果關係呢?如果量測變數不同怎麼辦?如果它是更可信的東西,比如阿爾茨海默氏症和老年怎麼辦?顯然,兩者之間存在相關性,但有因果關係嗎?許多人會錯誤地認為,是的,完全基於相關性的強度。謹慎行事,無論有意還是無意,統計研究中都將繼續存在相關性狩獵。
(3)
數據釣魚
這個誤導性的數據示例也被稱為“數據挖掘”(並且與有缺陷的相關性有關)。它是一種數據挖掘技術,其中分析大量數據以發現數據點之間的關係。尋求數據之間的關係本身並不是數據濫用,但在沒有假設的情況下這樣做是數據濫用。
數據挖掘是一種自私的技術,通常用於繞過傳統數據挖掘技術的不道德目的,以尋求不存在的額外數據結論。這並不是說沒有正確使用數據挖掘,因為它實際上會導致出人意料的異常值和有趣的分析。然而更多時候,數據挖掘被用來假設數據關係的存在而無需進一步研究。
通常,數據捕撈會導致研究因其重要或古怪的發現而廣為人知。這些研究很快就與其他重要或古怪的發現相矛盾。這些錯誤的相關性常常使公眾非常困惑,並尋找有關因果關係和相關性重要性的答案。
同樣,數據的另一種常見做法是遺漏,這代表著在查看大量數據集的答案後,您只選擇支持您的觀點和發現的那些,而忽略那些與它們相矛盾的答案。正如本文開頭所提到的,有三分之一的科學家承認他們的研究作業存在問題,包括隱瞞分析細節和修改結果!但話又說回來,我們面臨的一項研究本身可能屬於這
33% 的可疑做法、錯誤的民意調查、選擇性偏見……任何分析都變得難以置信!
(4)誤導性數據可視化
富有洞察力的圖形和圖表包括非常基本。。無論您選擇使用哪種類型的數據可視化,它都必須傳達:
-
使用的等級
-
起始值(零或其他)
-
計算方法(例如,數據集和時間段)
如果沒有這些元素,可視化數據表示應該被視為一粒鹽,考慮到一個人可能犯的常見數據可視化錯誤。如果它可以為所提供的資訊增加價值,還應識別中間數據點並給出上下文。隨著對可變數據點比較,智慧解決方案自動化的依賴日益增加,應在比較來自不同來源、數據集、時間和位置的數據之前實施最佳作業(即設計和縮放)。
(5)有目的和選擇性的偏見
下一個最常見的濫用統計數據和誤導性數據的例子可能是最嚴重的。有目的的偏見是故意試圖影響數據發現,甚至不假裝專業責任。最有可能採取數據遺漏或調整的形式來證明某個特定點。
對於那些不閱讀小行的人來說,選擇性偏差稍微謹慎一些。它通常落在被調查的人的樣本上。例如,被調查人群的性質:向一群大學生詢問法定飲酒年齡,或者向一群退休人員詢問養老制度。您最終會遇到一個稱為“選擇性偏差”的統計錯誤。為避免此問題,您應始終隨機選擇背景可能與調查主題相關或不相關的人。
當針對一個人進行整個分析時,企業和分析師容易產生偏見。無論此人是否注意到,他們都可能提供不準確或經過操縱的圖片來確認特定結論。由於錯誤資訊,這可能會導致決策失誤。
(6)
百分比變化與小樣本量相結合
另一種產生誤導性統計數據的方法,也與上述樣本的選擇有關,是所述樣本的大小。當以完全不顯著的樣本量進行實驗或調查時,不僅結果將無法使用,而且呈現它們的方式(即百分比)將完全誤導。
向 20
人的樣本量提出問題,其中 19 人回答“是”(=95%
表示是)與向 1,000 人提出相同問題,950
人回答“是”(也為
95%):百分比顯然不一樣。
僅提供變化百分比而不提供總數或樣本量將完全具有誤導性。
xkdc 的漫畫很好地說明了這一點,展示了“增長最快”的說法是如何完全相對的營銷演講:

同樣,所需的樣本量受您提出的問題類型、您需要的統計意義(臨床研究與商業研究)以及統計技術的影響。如果您進行定量分析,200
人以下的樣本量通常是無效的。
(7)
截斷軸
截斷軸是統計數據可能產生誤導的另一種方式。在建立圖表來描繪統計數據時,很自然地假設 X 和
Y
軸從零開始。截斷軸代表著做相反的事情。例如,以預定義的值開始軸,以便影響圖形被感知的方式以實現特定結論。這種技術經常在政治中被用來誇大一個原本不那麼有趣的結果。
讓我們以廣告中濫用統計數據的例子來說明這一點。下圖顯示了一張宣傳肯德基香脆雞肉捲的圖表,並將其卡路里與其他品牌的類似產品進行了比較。正如我們所見,這裡的
X 軸從 590 開始,而不是從零開始。這使得肯德基的包裝看起來只有Taco
Bell, Burger King, or Wendy的一半卡路里,而實際上只少了 70
卡路里。

資料來源:
Reddit “數據很醜”
這是一個明顯的示例,其中操縱軸以顯示具有誤導性的特定結果。截斷軸是一種非常危險的錯誤統計做法,因為它可以幫助圍繞重要主題建立錯誤的敘述。在這種情況下,它可能會產生錯誤的想法,認為產品比實際更健康。
(8)
策略性地選擇時間段
最後但並非最不重要的一點是,統計數據的常見誤用是策略性地選擇時間段來顯示結果。這是一個誤導性統計的案例,可以有目的地進行,以達到特定的結果,也可以是偶然的。例如,只選擇一個表現良好的月份來構建銷售報告將描繪出關於整體銷售業績的誤導性畫面。
無論有意與否,我們選擇描繪的時間段都會影響觀眾感知數據的方式。例如,顯示 3
個月的值可能會顯示與顯示超過一年的完全不同的趨勢。下圖是這種誤導性做法的一個很好的例子。您可以看到一張顯示
1995 年至 2016
年英國國債的圖表。如果您看到這張圖表,您顯然會認為英國的國債比以往任何時候都高。

資料來源:www.economicshelp.org
但是,當您查看更長的時間段時,例如
1910 年到 2015
年(下圖),我們意識到與其他年份相比,債務實際上非常低。讓這成為一個清晰的例子,說明我們選擇描繪的時間段如何顯著改變人們感知資訊的方式。

資料來源:www.economicshelp.org
如何避免和識別濫用統計數據?
現在我們已經查看了濫用統計數據的示例和常見案例,您可能想知道,我該如何避免所有這些?第一件事當然是站在誠實的調查/實驗/研究面前,選擇你眼前的那個,它應用了正確的數據收集和解釋技術。但是,除非您問自己幾個問題並分析您手中的結果,否則您無法知道。
作為一名企業家和前顧問
Mark Suster 在一篇文章中建議,您應該想知道誰對上述分析進行了初步研究。獨立大學學習小組、實驗室附屬研究團隊、諮詢公司?從那裡自然會產生一個問題:誰付錢給他們?由於沒有人免費工作,因此知道誰贊助了這項研究總是很有趣。同樣,研究背後的動機是什麼?科學家或統計學家試圖弄清楚什麼?最後,樣本集有多大,誰是其中的一部分?它的包容性如何?
這些是在到處傳播歪斜或有偏見的結果之前需要思考和回答的重要問題,即使它一直在發生,因為放大了。放大的典型例子經常發生在報紙和記者身上,他們獲取一份數據並需要將其變成頭條新聞,因此通常脫離其原始背景。沒有人買一本雜誌,上面寫著明年,XYZ
市場會發生和今年一樣的事情,儘管這是真的。編輯、客戶和人們想要新的東西,而不是他們知道的東西;這就是為什麼我們經常會出現一種放大現象,這種現象得到了回應,而且超出了應有的程度。
如果您是執行分析的人,例如為您的工作生成報告,您可以問自己一些相關問題以避免使用誤導性統計數據。例如,數據可視化是否準確地表示數據?(標籤清晰,軸從
0 開始,正確的圖表類型等)
研究是否以誠實和公正的方式表示?此數據中缺少哪些資訊?你也可以請你研究之外的人來查看數據,有人偏向於可以確認你的結果沒有誤導性的主題。
正如您在這篇文章中所看到的,通過一些有見地的不良統計示例來說明,以誤導的方式使用數據非常容易。如果您遵循上述所有步驟,您應該能夠對數據進行清晰的分析和正確使用。
濫用統計數據 -
總結
對於“可以操縱統計數據嗎?
”這個問題,我們可以解決經常使用的 8
種方法,有意或無意,它們會扭曲分析和結果。以下是濫用統計數據的常見類型:
詢問錯誤
有缺陷的相關性
數據釣魚
誤導性數據可視化
有目的和選擇性的偏見
結合小樣本數量使用百分比變化
截斷軸
策略性地選擇時間段
既然您了解了它們,就可以更容易地發現它們並質疑每天提供給您的所有統計數據。同樣,為了確保您與所閱讀的研究和調查保持一定的距離,請記住要問自己的問題,誰進行了研究,為什麼進行研究,誰為研究付費,樣本是什麼。
透明度和數據驅動的業務解決方案
雖然很明顯統計數據有可能被濫用,但它也可以在道德上推動數字世界的市場價值。大數據有能力為數字時代的企業提供效率和透明度的路線圖,並最終實現盈利。線上報告軟體等先進技術解決方案可以增強統計數據模型,並為數字時代的企業提供競爭優勢。
無論是市場情報、客戶體驗還是業務報告,數據的未來就是現在。注意以負責任、合乎道德和直觀的方式應用數據,並觀察透明的企業形象的發展。不時重溫這個有見地的不良統計示例列表,以提醒以正確方式使用數據的重要性! |