|
Javier Palarea-Albaladejo, Iain
McKendrick
VET RECORD | 18 January 2020
pp.59-64
需要知道什麼
周全到而且有效的實驗設計對於得到準確而有意義的結果至關重要。
•有關設計的決定必須基於研究的總體目標,關於目標生物學參數的明確定義,和計劃的統計分析決定。
•所有研究均應納入隨機因素,以使試驗設計在面對不確定性和未預料到的偏見來源時具有強韌性。
•在開始收集數據之前,進行檢定力分析以確定使用統計技術地檢測特定生物學效應所需的重複次數非常重要。
•選擇用於分析收集的數據的統計方法時,應基於對分析目標和數據性質的仔細考慮。
•必須考慮自變量和因變量的度量和分佈,因為這最終會影響符合哪些假設。
•雖然常規的做法是使用P值報告統計顯著性,但單獨的P值是一個有限的摘要數字,容易被誤用。在獸醫研究中,根據臨床上顯著的效應大小,報告結果可能更合適。
•隨著科學研究越來越以數據為驅動力,在專業項目中擁有化量專業知識將帶來巨大的好處。
最近技術和計算的發展促進了對於大量日益複雜的數據的收集和處理。同時也顯然支持更輕鬆地使用高級數據分析方法和尖端沿算法,至少在表面上簡單易用。確實,通過使用軟體工具可以大大簡化統計計算的技術,但是對於成功的最重要要求是對變化和不確定性的真正理解,因此必須具備完善的統計知識和概念。但是,隨著用於快速,半無監督性。數據處理和分析軟體運算的系統的急激增加,尤其是與新形式的複雜高量的數據相關系統,使用者越來越不了解要如何理解或知道進行評估的相關假設。新演算法和高級統計方法正不斷制定。在這些數據評估大都是主觀的,並且需要使用其他概念和方法。
一些研究人員可能將統計學視為一門學科,認為這是“必不可少的惡魔”,尤其參與研究並且被要求在進科學期刊的出版。然而,動物實驗的倫理考慮和經濟成本本身也應該足以鼓勵研究人員使用經過深思熟慮和嚴謹的統計分析,來支持可靠的科學結論。
許多影響科學研究的嚴重的問題通常是由於不良的實驗設計。對於統計概念的誤解,以及天真的使用強大的軟體計算所引起的。然而在回顧科學研究時,雖然過分偏重統計結果,有時甚至忽略了實際的生物學理相關性。但是研究者經常對於報導使用的方法和有關其使用的關鍵決定依據,往往自相矛盾。僅使用含糊甚至是誤導性的術語。
使用定量分析方法必須嚴格探索,和根據研究的科學目的和所收集數據的特徵,評估其適用性。不應該盲目的跟隨在研究途徑中的常規步驟。在獨特的研究中有無數的數據類型,各種方法論的方法,關鍵假設和特定於數據的問題,與其特定研究相關。對於結果和解釋的潛力其影響一定不能被低估。透明度是報告結論的前提。例如,當兩種有效方法導致結果衝突時,應予以承認,接受和討論。
此文章不是要尋求全面性的介紹統計學,但其目的在於提高人們對於影響實驗設計和數據分析的一些最常見問題的認識,尤其是針對動物研究的關注。同時提出支持更好實行的一般原則和指導。
實驗設計
實驗設計的理論已經很成熟,而有大量針對不同讀者的文獻,也有大量網路資源。1
實驗設計的目的是確定相關的生物的測量結果和實驗單位,從而定義適當的處理組並確定研究中應該進行實驗重複數目。周到且有效的實驗設計,明確關注於感興趣的生物量,對於獲得準確而有意義的結果十分重要。
任何設計的出發點都應該是對於研究的主要目標,被檢定的假設,可能會導致效果混淆或對設計和理解造成其他影響的邏輯因子或實際約束條件的明確理解;知曉觀測數據的主要可變性來源。基於對於變異的感知理解,使用的統計方法,例如區塊與其他共變量,以減少關鍵數量估計中的不確定性。
所有研究均應納入隨機因素,以使試驗設計在抵制不確定性和未預料到的偏差來源時,能保持穩健。
出於實際原因,盲目研究並非總是可行。但最好是在可能的情況下,消除可能引起明顯偏見的因子。通常平衡設計是更好的,可以提供統計上的穩健性並更好地估計處理效果。
有關設計的決定必須由研究的總體目標,有關目標其生物性參數的明確定義和計劃的統計分析來決定。應當預先指定的統計分析方案,並且在研究過程中不會因為初始結果進行更改。儘管在模型通稱較差的情況下可能會更改。這種“聯合”方法的重要性,在於估計目前正在進行的廣泛活動。促進使用結構化框架。以確保臨床試驗的目標,並傳導一致的研究設計,實施與分析。2
這種整體思維應該有助於避免根本的誤解。例如,對於組群之間平均值差異性的標準統計檢驗,是假設為平均值相等(即無治療效果)。這種虛無假設,目的在以觀察到的數據檢定是否拒絕其假設。
但是,未能找到足夠的證據來拒絕原來虛無假設,並不代表著均值相等。正如某些研究錯誤地得出的結論。相反,如果科學目標是確定各組之間的平均值響應是無顯著差別,則應使用等效性檢驗。其中虛無假設是各組不同。一如既往,統計假設的性質以及其設計和分析,嚴格地取決於科學目標。
檢定力分析
檢定力分析通過預先確定給定的信賴度(通常,通常設置為95%),來計算檢定特定生物學效果所需要的重複次數。為良好的實驗設計提供消息並提供支持。請注意,追溯檢定力計算並不重要。如果對先前的統計意義不重大的結果,執行這些操作,則它們不會對已執行的分析增加任何影響。
通常,任何檢定力計算都包含四個要素:樣本量(“更多數據”將提供更強的檢定結果,但成本更高),數據(變異性越高,更難檢定給予的影響性),感興趣的效果大小(此值越大,則分析能夠提供強有力的結果的可能性越大)和檢定力(虛無假設被拒絕的概率,常規目標是80%)。
變異性的估計通常被認為是外源性因素,最好是通過精心設計的先期研究或是通過文獻綜合得到。但是它可能會受到很大的不確定性。根據研究的背景,可能需要固定其他任意兩個元素,以使研究人員了解第三個元素受到的影響。例如如果將樣本量限制為一個特定值,並且研究人員對可能的效應數量(差異量)有清晰的認識,則可以得出檢定力的估計值。如果該數值比例大大高於80%,則他們可能希望減少樣本量以符合減少動物使用的要求。相反,如果檢定力很小,那麼進行動物研究是不道德的。在後一種情況下,研究人員應尋求進一步選擇最佳化實驗設計。
我們發現,生物學上有特定意義的效應量(effect
size)通常對研究人員而言具有挑戰性。尤其是對於新穎的實驗。許多人發現以絕對值而非相對於基線的百分比變化來指定效果大小是更容易地。例如,我們可能希望指定接種組相對於對照組的平均值減少瞭百分比,而對照組的消息可從以前的試驗中獲得。可替代地,樣本大小和期望檢定力可以指定。從而允許計算可被認為是至少達到指定檢定力,可檢測到的最小效果大小。後一個數量可以作為評估協議實驗(proposed
experiments)有效性的有用基準。
檢定力計算基於明確的假設,量化任何特定實驗成功的可能性,提出警告性建議結構,提供了有用的結構,從而可以明智地做出決策,從而警告協議的實驗是被嚴重過度或不足,從而支持更好地使用可用資源。它還可強迫研究人員考慮統計假設的性質,這是無價的。
重要的是要理解,檢定力計算是由必要的參數值的確定。僅對特定實驗設置中所考慮的生物量有效,並且還取決於計劃中的特定統計分析。僅在某些情況下,先前的檢定力計算才與新研究相關。當一項研究試圖探索多個目標時,應該進行單獨的檢定力計算(可能以不同的統計分析為依據),並合併為整個研究達成共識。
檢定力分析的電腦程式可使用於最基本的統計檢驗(例如,t檢驗,卡方檢驗和比例的二項式檢驗)以及簡單的變方分析和線性模型。對於更複雜的模型,只有通過隨機模擬才可能進行檢定力分析(即,使用電腦軟體在給定特定參數的情況下生成實驗的多種表現,分析這些模擬數據集並整理結果,以便憑經驗估算檢定力)
。
我們的經驗表明,檢定力計算本身可能不是最正面的好處,而是識別和修改下次最佳化實驗的設計。任何改進實驗設計的投資都會在統計,道德和經濟上獲得回報。
統計分析
統計科學是一門成熟的學科,已經產生了大量的統計檢定,模型和方法框架。在確定使用於分析實驗數據集的合適統計方法時,重要的是區分數值數據,分類數據,以及不同類型的數值數據。仔細考慮分析的目標,而數據的性質大大的限制相關的統計方法。
不幸的是,常常看到不恰當的統計方法被“壓制”使用於數據分析,這可能是因為研究人員已有使用該方法的經驗。但是,這不是選擇統計方法的適當標準。的確,統計方法的選擇將不可避免地受到分析師背景和建模問題概念的影響。如同最近的研究所示,由上述這些決定,所引起的分析方法的可變性,可能會選用方法產生明顯的影響3。
評估假設
確定了合理的方法後,重要的是要了解所有統計方法都受一組技術假設的約束,即使是被描述為“非參數”的假設,也不應將其誤認為是“沒有任何假設”。這應該是任何統計分析的關鍵部分,以確保合理地滿足這些假設。與數據預先假設的偏差很少會引起計算問題。因此,計算方法不會提供任何警告。但是假設錯誤將導致結果不可靠,可能無法反映實際的生物學特性。並且高估或低估了從數據中得出的統計證據的強度。因此,統計軟體使用者必須了解這些假設以及如何評估它們。
一個很好的例子是在不調整過度分散的數據情況下擬合(fitting)通用線性模型(generalized
linear model)。顯然的如果這種模型不適合使用。可以輕鬆測試過度分散是否存在,並且可以使用一個更好的模型對其進行解釋,因而避免了嚴重的後果,例如錯誤地將識別某因子是否具有統計意義的結果。然而這仍然是一個非常普遍的錯誤。
有些假設無法輕易評估。在實際應用中,很少討論一些高級假設(例如,關於可能的共變量或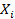 值測量誤差的存在)。儘管這種討論有時可能構成數據分析的重要組成部分。許多檢驗和模型的基本假設包括獨立性,分佈特性和變異量的均勻性。模型擬合後,殘差可提供有關這些潛在問題的豐富信息。 值測量誤差的存在)。儘管這種討論有時可能構成數據分析的重要組成部分。許多檢驗和模型的基本假設包括獨立性,分佈特性和變異量的均勻性。模型擬合後,殘差可提供有關這些潛在問題的豐富信息。
觀測值之間缺乏獨立性將在殘差圖中顯示模式,可以使用諸如Bartels等級測試之類的檢定以形式化此評估。對連續數具上進行量測的統計方法通常假定數據常正態分佈,而已圖形表示(如簡單的直方圖或分位數圖)以及正式的統計檢驗(例如,Kolmogorov-Smirnov或Shapiro-Wilk檢驗)都有助於評估是否常態分佈。變異數缺乏同質性也很容易在圖形上發現,並且可以使用特定測試進行評估(例如Bartlett或Levene測試)。
許多模型對於其分佈假設的中等偏差具有強韌性。數據缺乏獨立性或變異量異質性通常會對統計結果產生更嚴重的後果。在進行任何正式分析之前,進行數據探索性分析以幫助理解,使得數據可視化,這些好處不可低估。
數據轉換在處理模型假設的某些偏差,與測量數據變異數的常態性和均一性等相關的特殊性方面可能問題很有用。流行的選項包括針對數據不對稱性的對數變換,穩定變異量的平方根變換和標準化方法,以消除異類標度和度量單位的影響,並促進多個變量之間的比較。
但是,儘管數據轉換在實際中可能有用,但不應將其用作為於減輕對統計模型的不當選擇或掩蓋數據的不良特徵的影響。例如對於由計數組成的數據進行建模時,通常優先選使用通用線性模型,而不是在使用標準線性迴歸模型之前將數據轉換為連續尺度。同樣當異常觀察結果存在時,建議不要研究依賴於轉換貨是忽略此異常值。最好的方法是觀察此異常值是在不同過程產生,或是因為技術問題。通常,為了淡化離群值的影響,最好使用基於穩健(Robust)統計的方法。例如,用於穩健回歸分析的MM估計。
處理數據中不可忽略的複雜性會影響模型假設的有效性,通常需要在統計分析中增加複雜性。例如,在觀察數據的常見情況下,即動物來自同一窩或圈養在圍欄中,或者隨著時間的推移從同一動物收集數據。這種試驗,則是混合模型,即是稱為多級模型。允許包含隨機效應。這些可以用來解釋不同水準的變異性(例如在窩內,圍欄內的仔豬中觀察到的變異性)以及隨著時間的重複觀察中的自身相關性,因而提供了變異性的改進估計。
此外,通常從同一實驗單元收集具有不同屬性的多個觀察結果。在許多情況下,使用多變量數據分析方法同時檢查這些數據是最有意義。以便充分了解總體數據的結構和關鍵特徵,而不是孤立地查看每個度量。為了使清晰度最大化,數據分析應盡可能簡單以達到科學目標,但又不能過於簡單以至於忽略了數據的重要特徵。
P值
P值通常用於總結統計證據,因此支持科學結論。然而,不幸的是,這種以P值為中心的作用是存在著濫用,誤解和“
P hacking”的情況:一種有意或無意地偏向於發現小的P值。這種扭曲了科學研究並導致了可再現性危機。
變異性和不確定性是科學實驗必不可少的部分,統計分析的實質意義是要說明和量化實驗的這些結果,以更好地支持對生物的瞭解。孤立的P值是一個有限的總結,因此不建議僅僅基於P值其是否超出一個任意的臨界值來強調此科學陳述。報導一個P值不能代替對結果和有效科學推理的仔細檢查。統計界的最新工作,力求提高人們對科學研究中P值濫用的認識,以正確使用和解釋P值提供原則4。
一種廣為人知的方法可以破壞統計結果的有效性,即是通過對假設的偏倚或多重檢驗。如果假設被選擇地檢定或報告(因為數據的這一方面看起來很有趣),那麼對結果的“挑選”將導致報告的P值虛假地較低。這是在收集數據之前定義分析的基本原理之一,並且僅在明顯導致模型擬合性差的地方偏離。多重檢驗對於對許多假設是有問題的,因為執行的檢驗次數越多,從統計上講,即使原假設始終為真,它們也有可能一些會產生較小的P值。因此,在進行多次檢定,報告的P值將誇大其統計顯著性水準。
已經提出各種方法來調節P值。例如Bonferroni或Tukey校正值是很受歡迎的選項,儘管隨著比較次數的增加它們可能變得過於保守。另一方法是基於控制高維數據集中有興趣的信號,基於控制拒絕錯誤的無效假設的預期比例(即錯誤發現率),此替代方法已被證明是有效且嚴格的。建議研究人員保持警惕,應對多種測試所涉及的風險,在適當時調整P值。但應著重於從其統計模型中解釋關鍵參數的點估計值和信賴區間。因為它們可能在提高科學認識方面更有價值。
統計分析的報告
目標,假設,設計和數據分析都是相互作用影響,並且必須相互一致。應在科學報導的專門部分中應該明確說明和詳細描述:1.進行的每個分析的目的;2.涉及的變量以及對其進行的任何操作;3.方法的假設條件及其有效性;4.評估生物性相關結果的標準;5.使用的所有軟體列表;6.以及使用時相關的任何專門或制定例程的詳細消息。除了最初指定的分析之外,還應該進行任何臨時分析,並且通常應在探索性或指示性基礎上進行解釋。
以簡潔的表格總結了數值結果。該表格記錄了關鍵估計值以及相關的不確定性量測。
圖形可用於表示觀察到的數據,並在適當時可直觀地支持建模得出的結論。統計分析應始終報告結果不確定性的範圍,或某種程度的變異性,最好通過報告圍繞估計影響和/或數值顯著性水準的信賴區間。科學陳述應明確提其所依據的統計結果。
結論
隨著科學研究越來越以數據為驅動力,並且龐大且複雜的數據激增。嚴格的實驗設計,統計模型和解釋對於成功的科學發現,維持對科學工作的信譽以及價值的積極認識,都是必不可少。為了減輕本文章中強調的風險並推動良好實際方法,在進行研究之前和之後,進行正式的專家評審和對於研究定量因素的確認將是有幫助的。
考慮到研究使用複雜的方法論,以及進行有效的統計分析所涉及的大量工作,在研究項目中擁有專業的定量專業知識將帶來巨大的好處。訓練有素且經驗豐富的統計學家,可以作為專業的數據建模人員和解釋人員,可以廣泛地參與研究設計和數據分析的各種可能方法,提高執行效率,實施有助於促進可重複性和可再現性的實驗,促進報告中方法與結果的一致性。同時將統計結果獨立客觀地轉化為生物性見解,並且通常有助於減少科學研究中常見的統計問題的發生率。
但是,通過訓練,不斷提高獸醫和生物學家之間的統計複雜理論非常有價值。同樣的提高應用統計學家的生物學水準將導致更好的結果。在這種情況下,需要伴隨著期刊和編輯者對新方法或不熟悉方法的開放態度,以提高定量複雜性。
考慮到所有因子後,關鍵消息必須是科學研究越依賴可靠的統計結果。所使用的數據集和統計方法越複雜,那麼所有參與其中的人都必須遵守此文章中描述的良好做法,此因子就越重要。
作者:Javier
Palarea-Albaladejo, Iain McKendrick Biomathematics and Statistics
Scotland, Edinburgh, UK email:
[email protected]
doi:
10.1136/vr.m117
References
1. National
Centre for the Replacement, Refinement and Reduction of Animals in Research.
Experimental design.
www.nc3rs.org.uk/experimental-design
(accessed 6 January 2020)
2. International
Council for Harmonisation of Technical Requirements for
Pharmaceuticals for Human Use.
Estimands and sensitivity analysis in clinical trials. https://database.ich.org/sites/default/files/E9-R1_EWG_
Draft_Guideline.pdf (accessed 6 January 2020)
3. Silberzahn
R, Uhlmann EL, Martin DP, et al. Many analysts, one data set: making
transparent how
variations in analytic choices affect results. Adv Meth Pract Psychol
Sci 2018;1:337–56
4.
Statistical inference in the 21st century: a world beyond P<0.05. Am
Stat
2019;73
Supp 1
|